

こんにちは、フルオンチェーンNFTクリエイターのnawooです。
 nawoo
nawoo今回は、Three.jsを使ったフルオンチェーンNFTのRollerCoasterについて解説していきます。
まずは、昨年12月に投稿された、以下 xtremetom氏のツイートをご覧ください。
I continued exploring data compression and created this on-chain generative 3D roller coaster.
— xtremetom (@xtremetom) December 7, 2022
🎢 100% on-chain
🗜️ Compresses ~600kb (minified) scripts to ~200kb
✅ Uses native browser tech
👇🧵 pic.twitter.com/iQkAOaYZ2a
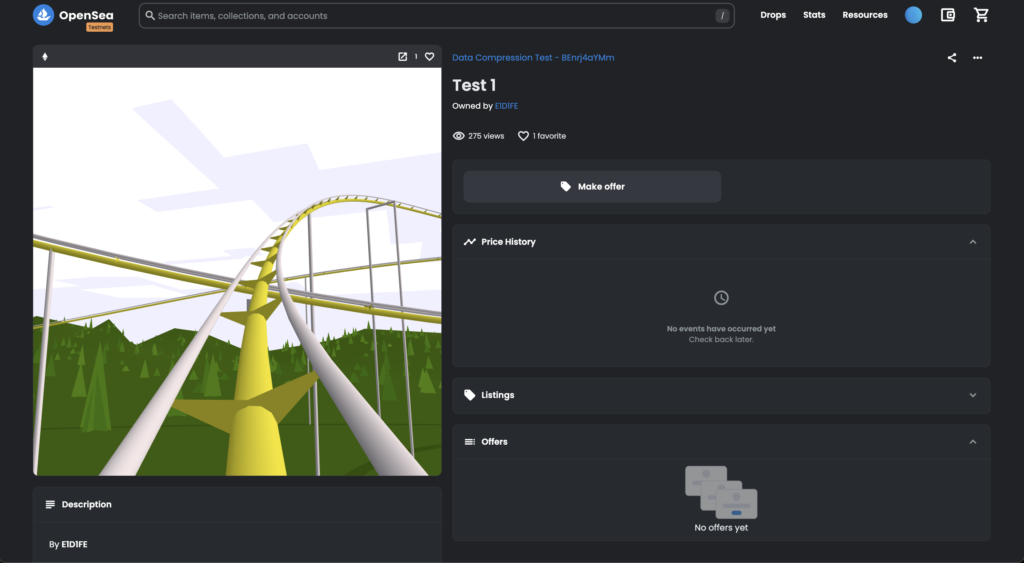
こちらは『Three.jsを使ったフルオンチェーンNFT』なのですが、先日記事で取り上げた「dom氏のROSES」とは異なる方法で作られているようです。

 nawoo
nawooさて、先ほど掲載した一連のツイートスレッドを読むと、「RollerCoaster」に関して以下のような説明がされています。
- すべてのJavaScriptをバンドル (1ファイルにまとめる)
- バンドルされたJavaScriptをPNG画像に変換する
- PNG画像を圧縮する
- PNG画像をBase64エンコードする
- 24KBごとに分割する
- SSTORE2を使ってオンチェーンに保存する
- Inline Assemblyを使ってデータを結合する
- ブラウザの標準機能を使って、PNG画像を元のJavaScriptコードに戻す
特に、「JavaScriptコードをPNG画像に変換する」という部分で驚いたのですが、実際にそのPNG画像がツイートされています。

どのようにしてJavaScriptコードをPNG画像に変換したのか、そして、どうやって元のJavaScriptコードに戻しているのかなど、非常に興味深い作品です。
nawooということで本記事では、フルオンチェーンNFT「RollerCoaster」について、ROSESと比較しながら解説していきます。
ちなみに、RollerCoasterのJavaScriptコードはThree.js公式サイトのexamplesにあるものだそうです。
・参考: threejs.org/examples/#webxr_vr_rollercoaster
でははじめに、この記事の構成について説明します。
まず、RollerCoasterではThree.jsも含めてすべてのJavaScriptファイルを1つにまとめられている点について触れていきます。
続いて、フルオンチェーンNFT「RollerCoaster」のコントラクトのtokenURIを確認していきます。
さらに、RollerCoasterのメインコントラクト「DataCompressionTest.sol」について解説していきます。
その後、データコントラクトの分割や結合を簡単に行うためのコントラクト「LibraryStorage.sol」について、基本的な使い方も含めて概観していきます。
最後に、RollerCoasterの手法を使って3DフルオンチェーンNFTを作成する手順などについて解説します。
本記事が、フルオンチェーンNFT「RollerCoaster」の概要や仕組み、3DフルオンチェーンNFTの開発手順などについて理解したいと思われている方にとって、少しでもお役に立てれば幸いです。
※本記事は一般的な情報提供を目的としたものであり、法的または投資上のアドバイスとして解釈されることを意図したものではなく、また解釈されるべきではありません。ゆえに、特定のFT/NFTの購入を推奨するものではございませんので、あくまで勉強の一環としてご活用ください。
イーサリアムnaviの活動をサポートしたい方は、「定期購読プラン」をご利用ください。
JavaScriptのバンドル
ROSESの場合は、Three.jsとメインのJavaScriptコードは別のファイルになっていました。しかしRollerCoasterの場合は、Three.jsも含めてすべてのJavaScriptファイルを1つにまとめられています。
JavaScriptファイルを1つにまとめる(バンドル)には、webpackを使います。
デメリットとしては、Three.jsも含めるとバンドルしたJavaScriptのコードが大きくなってしまうので、デプロイに必要なガス代が高くなってしまいます。
また、以下の記事で作成した3DフルオンチェーンNFTでは、ROSESのThree.jsを再利用していました。

ROSESのThree.jsは、独立したデータコントラクトとしてデプロイされているので、別のプロジェクトから再利用することができました。
tokenURIを確認しよう
まずは、コントラクトのtokenURIを確認してみましょう。
dataURLをデコードすると、メタデータはこのようになっていました。
{
"animation_url":"data:text/html,%3Cstyle%3Ehtml%2Cbody%7Bpadding%3A0%3Bmargin%3A0...",
"name":"Test 1"
}ROSESと同じように、animation_urlにHTMLが設定されていることが分かりますね。
HTMLの内容を確認してみると、styleタグが1つ、scriptタグが2つありました。ROSESに比べるとかなりシンプルですね。
2つのscriptを順に見ていきます。
<!-- style -->
<style>
html, body { padding: 0; margin: 0; }
</style>
<!-- script 1 -->
<script>
var data = 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAYgAAAGICA...mCC';
</script>
<body>
<!-- script 2 -->
<script src="data:text/javascript;base64,ZnVuY3Rpb24gaW5qZWN0U2NyaXB0K...pOw=="></script>
</body>PNG画像データの定義 (script 1)
script 1 ではdata変数が定義されており、data:image/png;base64,〜とあるので、Base64エンコードされたPNG画像であることが分かります。
デコードしてPNG画像を取り出してみると、xtremetom氏のツイートで紹介されていたものと同じ画像が出てきました。
392×392ピクセルの画像で、ファイルサイズは150KBでした。
JavaScriptコードをPNG画像に変換する仕組み
ツイートによると「バンドルされたJavaScriptコードをPNG画像に変換する」とのことですが、一体どのようにして変換しているのでしょうか。
PNG-32では、ピクセルごとに『RGBA』という4つのチャンネルが、それぞれ8ビット(=1バイト)で合計32ビットの情報を持ちます。
左上のピクセルから順に、RGBA, RGBA, RGBA, …と並んでいます。
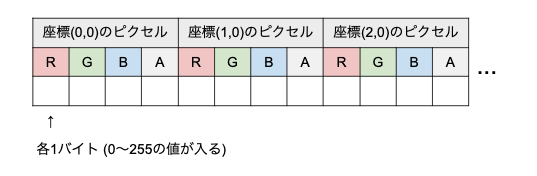
通常は、ピクセルごとの色情報をRGBAに格納します。(R=赤、G=緑、B=青、A=アルファチャンネル(透明度) )
例えば、赤色ならRGBA=(255,0,0,255)、黄色はRGBA=(255,255,0,255)、半透明の薄い青色はRGBA=(0,0,128,128)というように、色情報を格納します。
 nawoo
nawooこの色情報を格納する場所に、強引にJavaScriptコード(=文字列)を格納したわけです。
例として、Hello World!という文字列を格納してみます。 Hello World!をバイト(0〜255)で表すと 72,101,108,108,111,32,87,111,114,108,100,33 の12バイトです。1ピクセルが4バイトなので、3ピクセルの画像に格納できます。
- 座標(0,0)のピクセルのRGBAには、
H、e、l、lを格納 - 座標(1,0)のピクセルのRGBAには、
o、W、oを格納 - 座標(2,0)のピクセルのRGBAには、
r、l、d、!を格納
座標(0,0)のピクセルはRGBA=(72,101,108,108)となり、カラーコードでは #48656c6c となります。
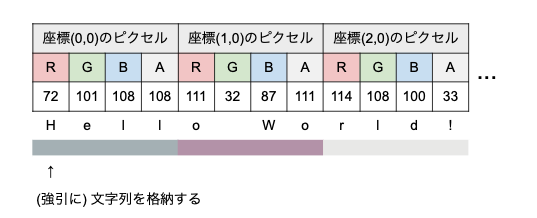
このような方法で、文字列をピクセルデータに変換することができます。
 nawoo
nawooこのようにして作成した画像をPNG形式で保存すると、圧縮されるという仕組みです。
先ほどのツイートのPNG画像は392×392ピクセルのサイズだったので、392x392x4=614,656バイトの情報が格納されていることがわかります。
614KBのJavaScriptコードをPNG画像として圧縮することで、150KBまで減らすことができたのです。
nawooPNG画像は可逆圧縮なので元のデータを失うことなく復元できます。JPGなど不可逆圧縮のタイプでは、この圧縮方法は使えません。
実際にJavaScriptコードからPNG画像を作る方法は、後ほど紹介します。
PNG画像からJavaScriptコードを復元 (script 2)
script 2は、PNG画像から元のJavaScriptコードを復元するためのコードです。
<!-- script 2 -->
<script src="data:text/javascript;base64,ZnVuY3Rpb24gaW5qZWN0U2NyaXB0K...pOw=="></script>src属性に、Base64エンコードされたJavaScriptコードが指定されているので、これをデコードしてみました。
nawooMinifyされていたので、読みやすく修正したのがこちらです。
function injectScript(data) {
// canvasタグを作成
const canvas = document.createElement('canvas');
const gl = canvas.getContext('webgl');
// テクスチャを作成
const texture = gl.createTexture();
gl.bindTexture(gl.TEXTURE_2D, texture);
// Imageを作成してdata(PNG画像)を読み込む
const image = new Image();
image.src = data; // ※1
image.addEventListener('load', function () {
const w = image.width;
const h = image.height;
// テクスチャを使用する準備
gl.bindTexture(gl.TEXTURE_2D, texture);
gl.texImage2D(gl.TEXTURE_2D, 0, gl.RGBA, gl.RGBA, gl.UNSIGNED_BYTE, image);
gl.generateMipmap(gl.TEXTURE_2D);
// フレームバッファを作成
const framebuffer = gl.createFramebuffer();
gl.bindFramebuffer(gl.FRAMEBUFFER, framebuffer);
// フレームバッファにテクスチャを割り当て
gl.framebufferTexture2D(gl.FRAMEBUFFER, gl.COLOR_ATTACHMENT0, gl.TEXTURE_2D, texture, 0);
if (gl.checkFramebufferStatus(gl.FRAMEBUFFER) == gl.FRAMEBUFFER_COMPLETE) {
const buffer = new Uint8Array(w * h * 4);
// フレームバッファから一括でピクセルデータを読み込む
gl.readPixels(0, 0, w, h, gl.RGBA, gl.UNSIGNED_BYTE, buffer); // ※2
// ピクセルデータを文字列(JavaScriptコード)に変換して、Base64エンコード
const decoder = new TextDecoder('utf-8');
const b64 = btoa(decoder.decode(buffer)); // ※3
// scriptタグの作成
const script = document.createElement('script');
// srcにdataURL化したJavaScriptコードを指定
script.setAttribute('src', 'data:text/javascript;base64,' + b64.trim()); // ※4
// documentにscriptタグを追加
document.head.appendChild(script);
}
// canvasタグを削除
canvas.remove();
});
}
// data(PNG画像)を引数に渡して実行
injectScript(data);injectScript関数では、以下の処理を行なっています。
data変数に入っているPNG画像のdataURLをテクスチャとして読み込む (※1)- テクスチャのピクセルデータを
readPixelsでバイト配列(Uint8Array)として読み込む (※2) - TextDecorderでバイト配列(Uint8Array)から文字列(JavaScriptコード)にデコードする (※3)
scriptタグを生成してsrc属性にJavaScriptコードを設定する (※4)
nawooこれらは外部ライブラリを一切使わずに、すべてJavaScriptの標準機能で実装しています。
ROSESの場合は、データをgzipで圧縮して外部ライブラリのfflateで復元していたため、fflateをデータコントラクトから読み込む処理が別途必要でした。しかし、RollerCoasterでは外部ライブラリを読み込む必要はありません。
また、PNG画像の圧縮とgzipの圧縮はどちらもDEFLATEというアルゴリズムを使っているので、圧縮効率はほとんど同じです。
xtremetom氏の発言によると、Three.jsを圧縮した場合にgzipでは200KBだったのが、PNG画像の圧縮では199KBだったそうです。ほんの少しですがPNG圧縮の方が小さくなっています。
このことからも、PNG画像を使ってJavaScriptコードを圧縮するのは、非常に優れた手法だと言えるのではないでしょうか。
メインコントラクト
nawooRollerCoasterのメインコントラクトは、DataCompressionTest.solです。ROSESに比べるとシンプルなものになっています。
tokenURI関数
tokenURI関数では、animation_urlとnameを含むメタデータ(JSON)を作成しています。
addCodeLibrariesAsImage関数でscript 1(PNG画像の定義)を作成し、 addRenderCode関数でscript 2(JSコードの復元)を作成しています。
function tokenURI(uint256 tokenId) public view override returns (string memory) {
string memory tokenIdStr = uint2str(tokenId);
return
string.concat(
BEGIN_JSON,
string.concat(
BEGIN_METADATA_VAR("animation_url", false),
"data%3Atext%2Fhtml%2C", // data:text/html,
"%253Cstyle%253Ehtml%252Cbody%257Bpadding%253A0%253Bmargin%253A0%253B%257D%253C%252Fstyle%253E", // <style>...</style>
addCodeLibrariesAsImage(), // ← ここで script 1 を作成
"%253Cbody%253E", // <body>
addRenderCode(), // ← ここで script 2 を作成
"%253C%252Fbody%253E", // </body>
END_METADATA_VAR(false),
BEGIN_METADATA_VAR("name", false), // name="Test 1"
"Test%20",
tokenIdStr,
"%22",
END_JSON
)
);
}addCodeLibrariesAsImage関数
addCodeLibrariesAsImage関数では、script 1を作成しています。
Base64エンコードされたPNG画像データは、LibraryStorageコントラクトを使って読み込んでいます。
function addCodeLibrariesAsImage() internal view returns (string memory) {
LibraryStorage libraryStorage = LibraryStorage(_libStorageAddress);
return
string.concat(
BEGIN_SCRIPT,
"var%2520data%2520%253D%2520%2522", // var data = "
"data%253Aimage%252Fpng%253Bbase64%252C", // data:image/png;base64,
libraryStorage.getLibrary("RollerCoaster"), // ←ここでPNG画像を読み込む
"%2522%253B", // ";
END_SCRIPT
);
}作成されるコード(script 1)はこちらです。
nawooPNG画像がdataURL形式で定義されています。
<script>
var data = 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAYgAAAGICA...mCC';
</script>addRenderCode関数
addRenderCode関数は、PNGからJavaScriptコードを復元するためのscript 2を作成します。
renderCode変数に、Base64エンコードしたJavaScriptが入っています。
function addRenderCode() internal view returns (string memory) {
string memory renderCode = "ZnVuY3Rpb24gaW5qZWN0U2NyaXB0KGUpe2NvbnN0IHQ9ZG9jdW1...pOw==";
return
string.concat(
BEGIN_SCRIPT_DATA,
"data%253Atext%252Fjavascript%253Bbase64%252C", // data:text/javascript;base64,
renderCode,
END_SCRIPT_DATA
);
}作成されるコード(script 2)はこちらです。
<script src="data:text/javascript;base64,ZnVuY3Rpb24gaW5qZWN0U2NyaXB0K...pOw=="></script>LibraryStorageコントラクト
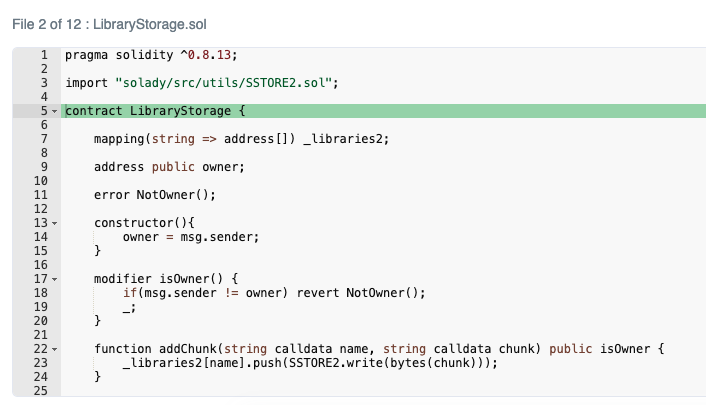
LibraryStorage.solは、データコントラクトの分割や結合を簡単に行うためのコントラクトです。
ROSESでは、Three.jsを9つのデータコントラクトに分割して保存し、 データを読み込む際にはDataChunkCompiler.solのcompile9関数で9つのアドレスを指定して結合していました。
基本的な使い方
分割データの保存には addChunk関数、データの結合には getLibrary関数を使います。
データを保存するまでの手順は以下のようになります。
- JavaScriptコードを一つにまとめる(バンドル) → 614KB
- PNG画像に変換して圧縮 → 150KB
- PNG画像をBase64エンコード → 200KB
- 24KBごとに9つに分割してLibraryStorageコントラクトの
addChunk関数で保存する
9つの分割データをaddChunk関数で保存する際には、同じ名前("RollerCoaster")を指定して保存します。
// 分割データの保存
libraryStorage.addChunk("RollerCoaster", chunk1);
libraryStorage.addChunk("RollerCoaster", chunk2);
...
libraryStorage.addChunk("RollerCoaster", chunk8);
libraryStorage.addChunk("RollerCoaster", chunk9);データ読み込む際は、getLibrary関数を使います。
nawooこのとき名前("RollerCoaster")を指定するだけで、9つの分割データを1つに結合した状態で取得できます。
// データの読み込み
libraryStorage.getLibrary("RollerCoaster"), // ←これだけで9つのデータコントラクトを結合したものを取得自分でデータコントラクトのアドレスを管理しなくても、名前を付けて保存し、名前を指定して読み込みができるので、とても便利です。まるでパソコンでファイルを扱っているかのようです。
余談ですが、この仕組みを更に進化させた「EthFS: Ethereum File System」というプロジェクトがあります。
誰でもファイルをブロックチェーン上にアップロードして、ファイル名を指定して簡単に呼び出せるという仕組みで、p5.jsのような大きなファイルもアップロードされています。
addChunk関数
addChunk関数では、SSTORE2を使って分割データを保存しています。
SSTORE2.writeでデータを書き込み、戻り値のアドレスを名前ごとに用意された配列に追加しています。
mapping(string => address[]) _libraries2; // 名前 => アドレス配列 のマッピング
...
function addChunk(string calldata name, string calldata chunk) public isOwner {
// SSTORE2.writeの戻り値(=データコントラクトのアドレス)を配列に追加する
_libraries2[name].push(SSTORE2.write(bytes(chunk)));
}getLibrary関数
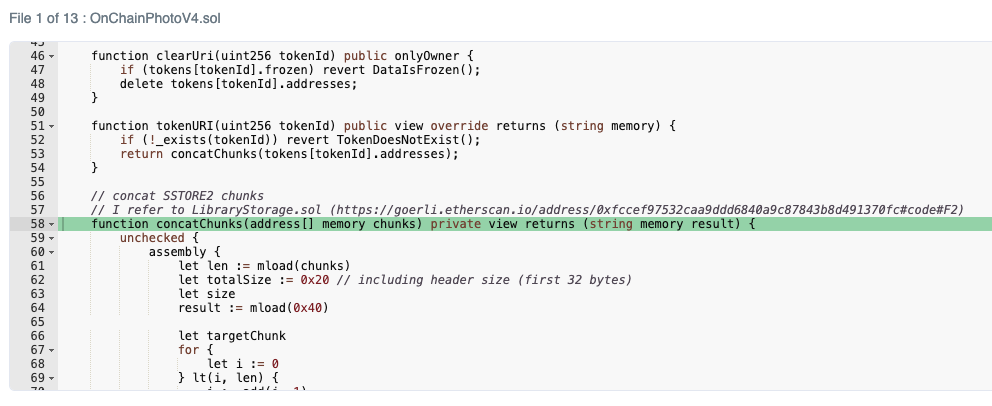
getLibrary関数は、複数のデータコントラクトから読み込んだデータを結合しますが、 ガス節約のためにInline Assemblyを使っています。
ROSESやSSTORE2を使ったケースと比較してみましょう。ROSESで使っているDataChunkCompiler.solのcompile9関数では、 各データコントラクトから読み込んだデータをabi.encodePackedで結合しています。
nawooこの場合、各データdata1.data()〜data9.data()は一旦メモリ領域に確保され、 それとは別に結合後の値もメモリ領域に確保されるので、メモリを多く使ってしまいます。
// 9つのデータコントラクト(Three.js)を結合する (ROSESの場合)
function compile9(address chunk1, address chunk2, ... address chunk8, address chunk9)
public view returns (string memory) {
IDataChunk data1 = IDataChunk(chunk1);
IDataChunk data2 = IDataChunk(chunk2);
...
IDataChunk data8 = IDataChunk(chunk8);
IDataChunk data9 = IDataChunk(chunk9);
return string(abi.encodePacked(
data1.data(),
data2.data(),
...
data8.data(),
data9.data()
));
}また、SSTORE2.readを使う場合は、各データコントラクトからデータを読み込んで、 abi.encodePackedやbytes.concatを使ってデータを結合します。
// SSTORE2.readを使ったデータ結合例
function concat(address chunk1, address chunk2, ... address chunk8, address chunk89)
public view returns (string memory) {
return string(abi.encodePacked(
SSTORE2.read(chunk1),
SSTORE2.read(chunk2),
...
SSTORE2.read(chunk8),
SSTORE2.read(chunk9),
));
}一方、LibraryStorageのgetLibrary関数では、SSTORE2.read関数を使わずにInline Assemblyを使い、個々のデータをメモリ領域に確保することなく、結合後の変数のメモリ領域に直接書き込んでいきます。
function getLibrary(string calldata name) public view returns (string memory o_code) {
// マッピングからデータコントラクトのアドレス配列を取得
address[] memory chunks = _libraries2[name];
unchecked {
assembly {
// アドレス配列のサイズ(=データの分割数)
let len := mload(chunks)
// トータルサイズ(データ結合後のデータサイズ+ヘッダ分の32バイト)
let totalSize := 0x20 // ヘッダ分の32バイトを最初に追加しておく
// 各分割データのサイズ
let size
// 戻り値(o_code)のポインタを取得
o_code := mload(0x40) // free memory pointerから読み込み
// 分割データの数だけループ
let targetChunk
for {
let i := 0
} lt(i, len) {
i := add(i, 1)
} {
// i番目の分割データのアドレスを取得 (chunks[i])
targetChunk := mload(add(chunks, add(0x20, mul(i, 0x20))))
// 分割データのサイズを取得
size := sub(extcodesize(targetChunk), 1)
// データコントラクトからデータをコピー (SSTORE2.readと同じ)
extcodecopy(targetChunk, add(o_code, totalSize), 1, size)
// トータルサイズを更新
totalSize := add(totalSize, size)
}
// 戻り値(o_code)のヘッダにデータサイズを保存
mstore(o_code, sub(totalSize, 0x20))
// free memory pointerを更新(トータルサイズにパディングを追加して32バイト単位に揃える)
mstore(0x40, add(o_code, and(add(totalSize, 0x1f), not(0x1f))))
}
}
}Inline Assemblyで直接メモリ操作する場合は、まずfree memory pointer(0x40)から空きメモリのポインタを読み込みます。
nawoobytesやstringでは、先頭の32バイト(ヘッダ)にデータサイズを格納し、その次からデータを書き込みます。メモリ操作が終わったら、free memory pointerを更新します。
上のコードでは、以下の処理をすることで、個々の分割データをメモリに確保することなく、データの結合を行っています。
- free memory pointerから戻り値(o_code)のポインタを取得
- totalSizeの初期値を32に設定 (ヘッダの分を先にすすめる)
- 分割データの数だけループ
- 分割データをo_code+totalSizeの位置にコピー
- totalSizeに分割データのサイズを追加して更新
- o_codeのヘッダにtotalSizeを書き込む
- free memory pointerを更新する

実際に作ってみました

この続き: 1,927文字 / 画像3枚
まとめ

今回は、フルオンチェーンNFT「RollerCoaster」について、ROSESと比較しながら解説を行いました。
本記事が、フルオンチェーンNFT「RollerCoaster」の概要や仕組み、3DフルオンチェーンNFTの開発手順などについて理解したいと思われている方にとって、少しでもお役に立ったのであれば幸いです。
また励みになりますので、参考になったという方はぜひTwitterでのシェア・コメントなどしていただけると嬉しいです。
🧭Three.jsを使ったフルオンチェーンNFT「RollerCoaster」について書きました
— イーサリアムnavi🧭 (@ethereumnavi) February 10, 2023
💡全てのJavaScriptを1ファイルにまとめ
💡PNG画像に変換・圧縮・分割しオンチェーン格納
💡ブラウザの標準機能を使い、PNG画像を元のJavaScriptコードに戻すという斬新手法
詳しくはこちら👇https://t.co/7z7sMUXmGR
今回ご紹介したRollerCoasterは、dom氏のROSESとは異なる手法で作られており、特に「PNG画像を使った圧縮方法」には驚いた次第です。
nawooROSESに刺激を受けて、新しい手法やプロジェクトがグローバルで次々に生まれてきています。今後の展開がとても楽しみですね。
また、本記事のコントラクトやスクリプトはこちらのGitHubで公開しています。記事中では説明しきれなかった部分もありますので、ぜひ参考にしてください。

イーサリアムnaviを運営するSTILL合同会社では、web3/crypto関連の記事執筆業務やリサーチ代行、その他(ご依頼・ご提案・ご相談など)に関するお問い合わせを受け付けております。
まずはお気軽に、こちらからご連絡ください。
- 法人プランLP:https://ethereumnavi.com/lp/corporate/
- Twitter:@STILL_Corp
- メールアドレス:info@still-llc.com